V22: Intrinsic Predictive Gradient
V22: Intrinsic Predictive Gradient
Period: 2026-02-19. Substrate: + within-lifetime gradient descent on energy prediction.
The key mechanism: Each environment step, the agent predicts its own energy delta, observes the truth, and updates its phenotype via SGD. The computational equivalent of the free energy principle: minimize surprise about your own persistence. No external reward, no human labels.
| Metric | Seed 42 | Seed 123 | Seed 7 | Mean |
|---|---|---|---|---|
| Mean robustness | 0.965 | 0.990 | 0.988 | 0.981 |
| Mean | 0.106 | 0.100 | 0.085 | 0.097 |
| Mean pred MSE | 6.4e-4 | 1.1e-4 | 4.0e-4 | 3.8e-4 |
| Final LR | 0.00483 | 0.00529 | 0.00437 | 0.00483 |
Within-lifetime learning is unambiguously working (100-15000x MSE improvement per lifetime, 3/3 seeds). LR not suppressed — evolution maintains learning. But robustness not improved over .
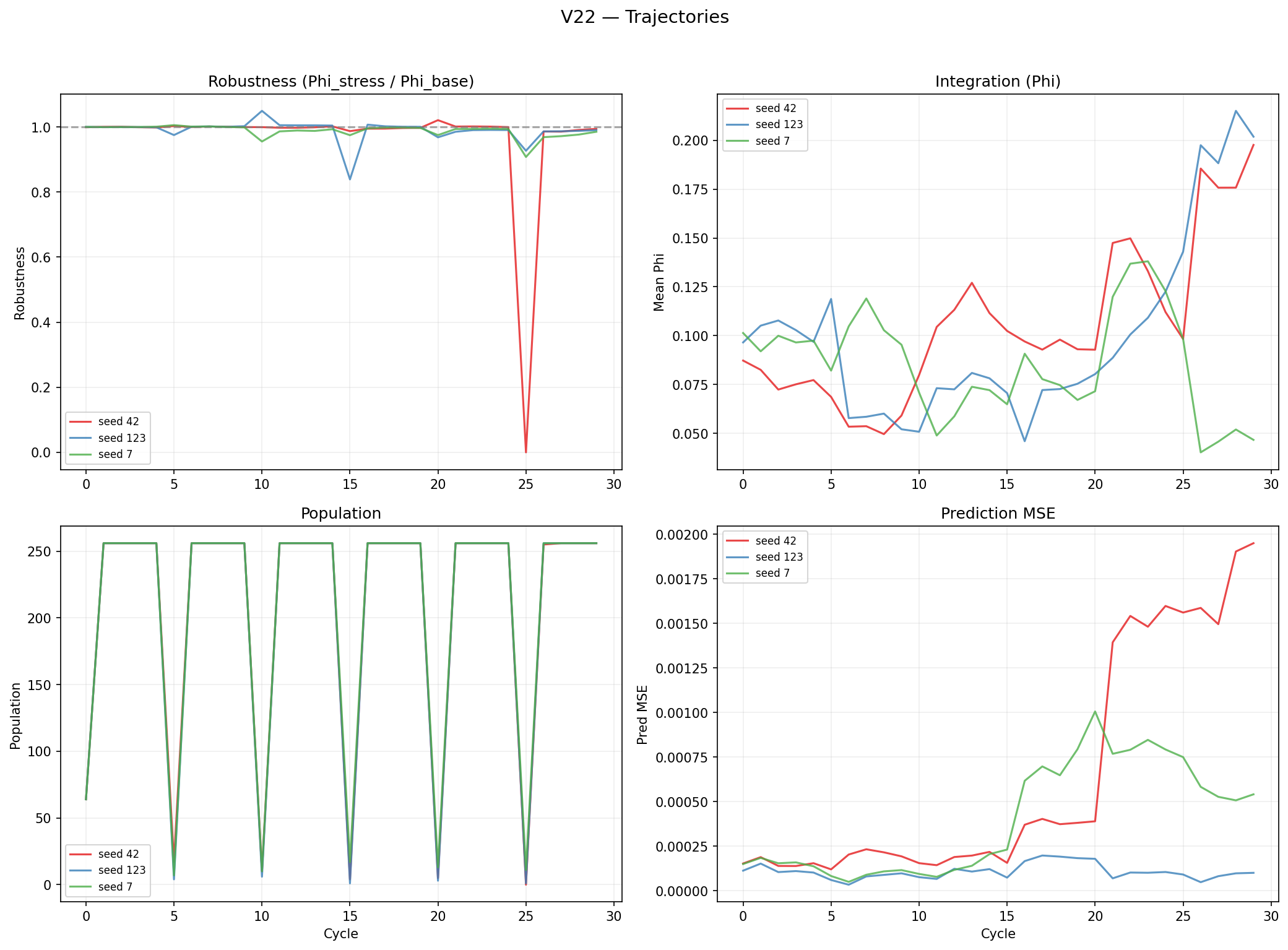

Prediction ≠ integration. The gradient makes agents better individual forecasters without creating cross-component coordination. A single linear prediction head can be satisfied by a subset of hidden units — no cross-component coupling required. This is the decomposability problem: linear readouts are always factored.
Source code
Study record — canonical metadata, result path, status, seeds, and key finding.
- — Within-lifetime SGD + genome/phenotype
- — Evolution with gradient learning
- — GPU runner (~10 min on A10)