The Emergence Experiment Program
The Emergence Experiment Program
Thirteen measurement records on and its precursor snapshots, testing whether persistence, world modeling, abstraction, communication, counterfactual reasoning, self-modeling, affect structure, perceptual mode, normativity, and social integration emerge in a substrate with zero exposure to human affect concepts. For , the shared protocol is 3 seeds, 7 snapshots per seed, and 50 recording steps per snapshot. and are the substrate and existence gates that make the later measurements meaningful.
Experiment 0: Substrate Engineering
Status: Complete. content-based coupling Lenia with lethal resource dynamics. Foundation for all subsequent measurement experiments.
This is not a result about affect by itself; it is the substrate-control record. The question is whether the system produces long-running, perturbable trajectories with enough internal structure to justify measuring world models, self-models, and social integration later. The answer is yes, but with an important limit: improves on earlier convolution-only substrates without breaking the agency wall.
Source code
Study record — canonical metadata, result path, status, seeds, and key finding.
- — Content-coupling Lenia substrate
- — Evolution loop with lethal resource dynamics
- — Baseline runner
Experiment 1: Emergent Existence
Status: Complete. Patterns persist, maintain boundaries, and respond to perturbation. Established by , confirmed in .
This is the first gate against over-interpreting the archive. Before asking whether a pattern has a world model, the program checks whether there is a persisting pattern to measure at all. and establish persistence and perturbation response; provides the content-coupled substrate used for the later analyses.
Source code
Study record — canonical metadata, result path, status, seeds, and key finding.
- — Initial Lenia substrate family
- — Evolution loop for persistence and robustness checks
- — Attention-based Lenia substrate
- — Attention substrate evolution loop
- — Content-coupled confirmation substrate
- — V13 evolution loop
Experiment 2: Emergent World Model
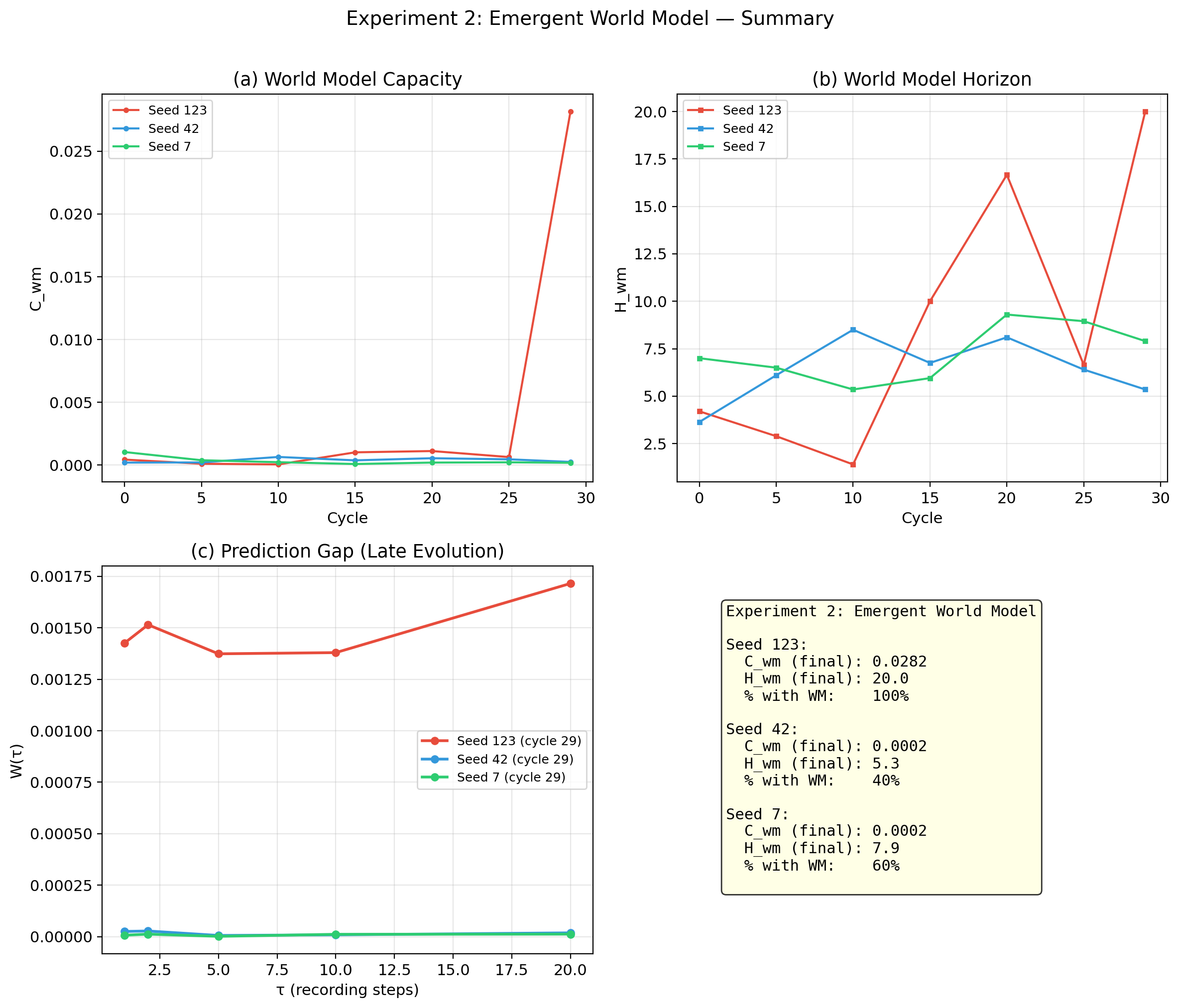
Question: When does a pattern's internal state carry predictive information about the environment beyond current observations?
Method: Prediction gap using Ridge regression with 5-fold CV.
| Seed | (early) | (late) | (late) | % with WM |
|---|---|---|---|---|
| 123 | 0.0004 | 0.0282 | 20.0 | 100% |
| 42 | 0.0002 | 0.0002 | 5.3 | 40% |
| 7 | 0.0010 | 0.0002 | 7.9 | 60% |
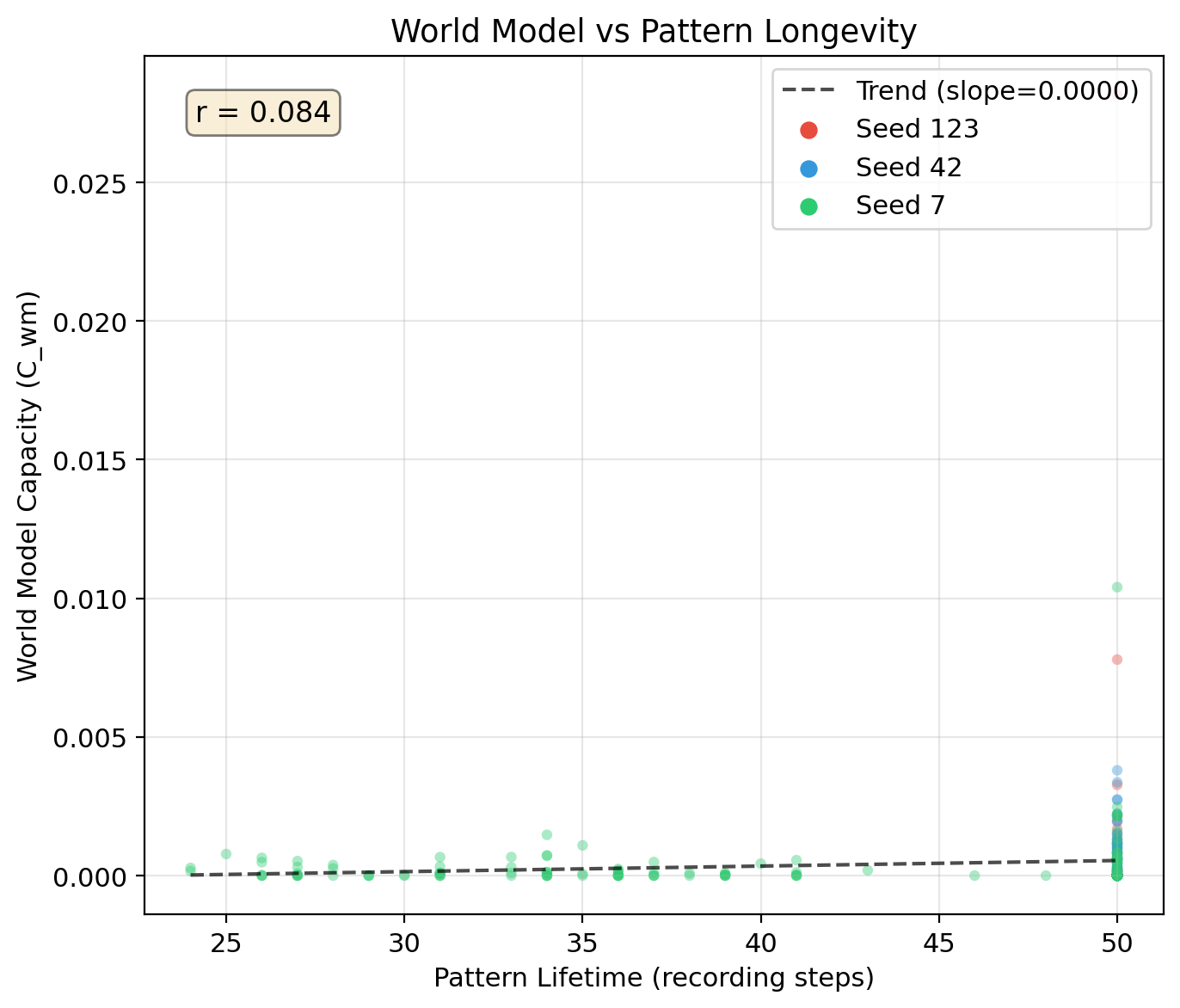
Finding: World model signal present but weak. Seed 123 at bottleneck shows 100x amplification. World models are amplified by bottleneck selection, not gradual evolution. To be clear about magnitude: for most seeds means the internal state predicts the environment barely better than the environment alone. Only seed 123 at maximum bottleneck pressure reaches 0.028 — detectable but still small. These patterns are not building substantial world models; they carry a faint trace of environmental predictive information, amplified briefly under extreme selection.
Source code
Study record — canonical metadata, result path, status, seeds, and key finding.
- — World model measurement
- — Runner
- — Visualization
Experiment 3: Internal Representation Structure
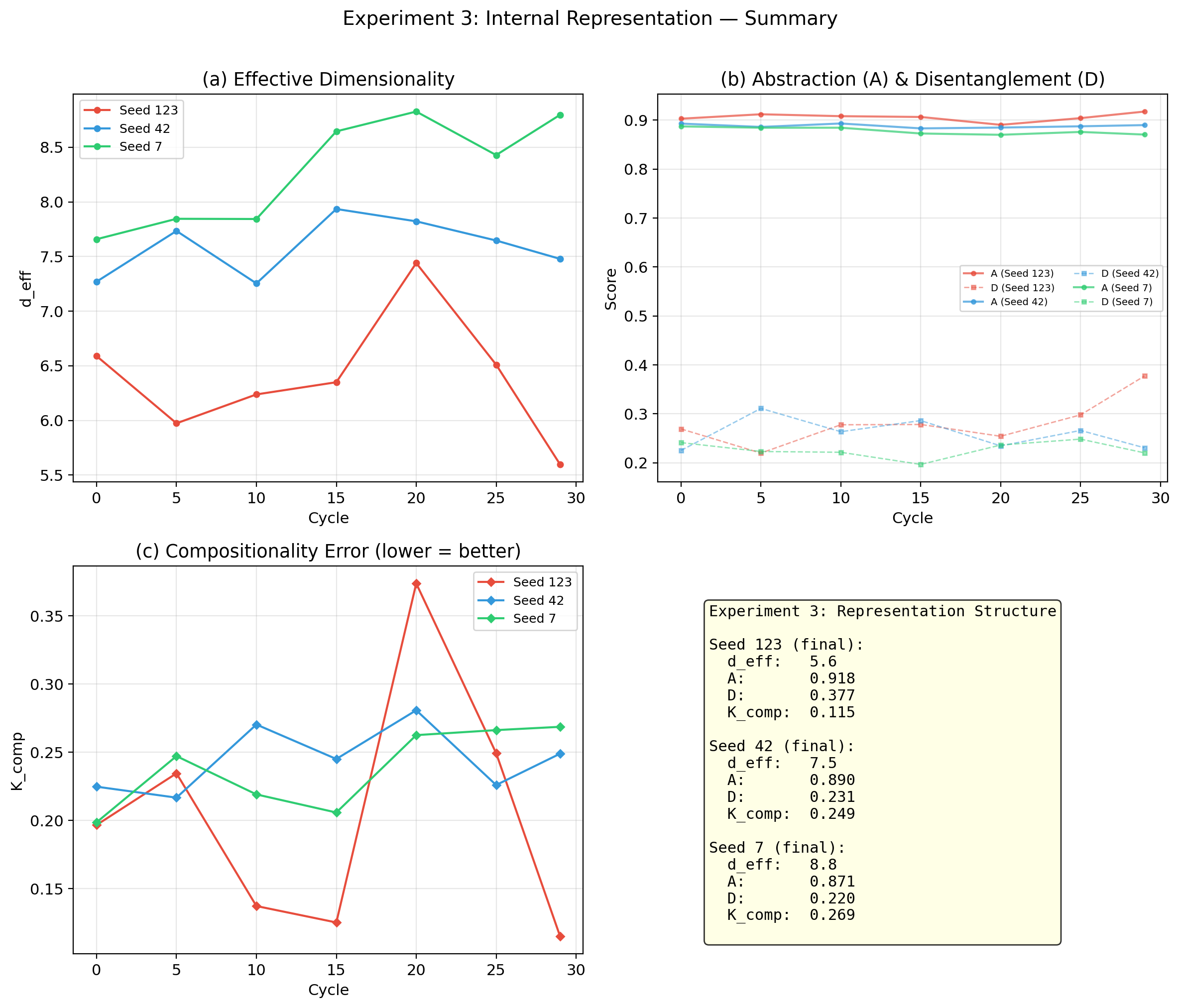
Question: When do patterns develop low-dimensional, compositional representations?
| Seed | (early to late) | |||
|---|---|---|---|---|
| 123 | 6.6 to 5.6 | 0.90 to 0.92 | 0.27 to 0.38 | 0.20 to 0.12 |
| 42 | 7.3 to 7.5 | 0.89 to 0.89 | 0.23 to 0.23 | 0.23 to 0.25 |
| 7 | 7.7 to 8.8 | 0.89 to 0.87 | 0.24 to 0.22 | 0.20 to 0.27 |
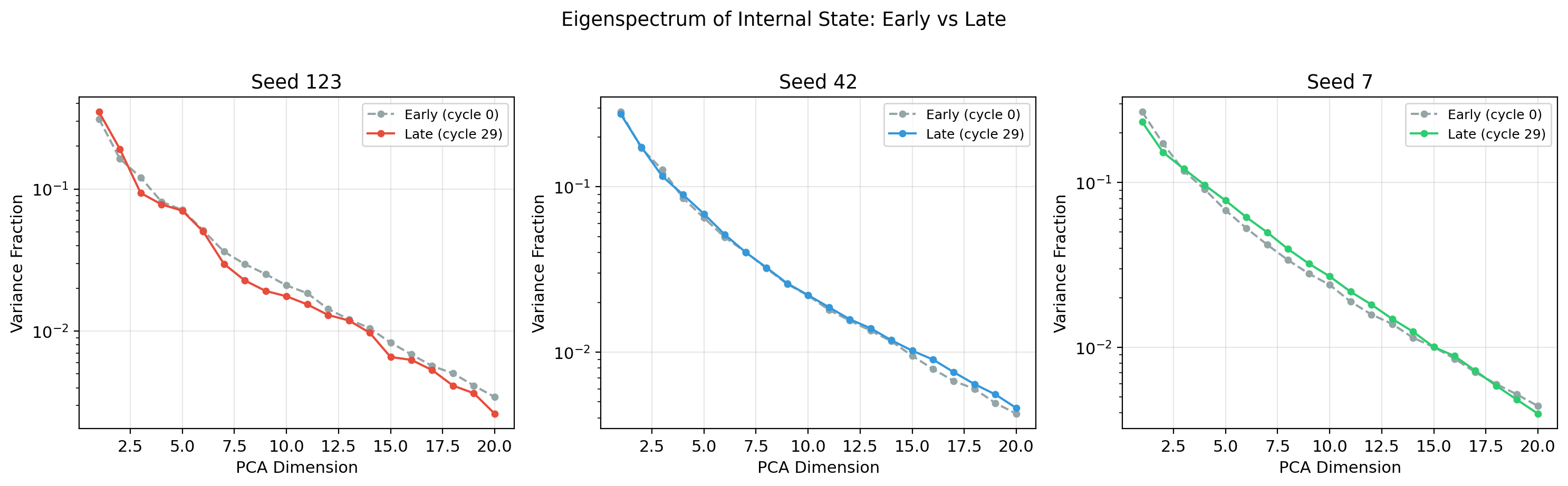
Finding: Compression is cheap — /68 from cycle 0. But quality only improves under bottleneck selection. Note the asymmetry: abstraction () is high and stable from the start — the system compresses efficiently without effort. But disentanglement () remains low — the compressed representations are tangled, not cleanly factored. Disentanglement requires active information-seeking that this substrate lacks.
Source code
Study record — canonical metadata, result path, status, seeds, and key finding.
- — Representation analysis
- — Runner
- — Visualization
Experiment 4: Emergent Language and Multi-Agent Culture
Question: When do patterns develop structured, compositional communication?
| Seed | MI significant | MI range | significant |
|---|---|---|---|
| 123 | 4/6 | 0.019-0.039 | 0/6 |
| 42 | 7/7 | 0.024-0.030 | 0/7 |
| 7 | 4/7 | 0.023-0.055 | 0/7 |
Finding: Chemical commons, not proto-language. MI above baseline in 15/20 snapshots but everywhere. Unstructured broadcast, not language.
Source code
Study record — canonical metadata, result path, status, seeds, and key finding.
- — Communication analysis
- — Runner
Experiment 5: Counterfactual Detachment
Question: When do patterns decouple from external driving and run offline world model rollouts?
Result: Null. from cycle 0. Patterns are inherently internally driven. The FFT convolution kernel integrates over the full grid — there is no reactive-to-autonomous transition because the starting point is already autonomous.
Source code
Study record — canonical metadata, result path, status, seeds, and key finding.
- — Counterfactual measurement
- — Runner
Experiment 6: Self-Model Emergence
Question: When does a pattern predict itself better than an external observer can?
Result: Weak signal at bottleneck only. everywhere. appears once: seed 123, cycle 20, one pattern at .
Source code
Study record — canonical metadata, result path, status, seeds, and key finding.
- — Self-model measurement
- — Runner
Experiment 7: Affect Geometry Verification
Question: Does the geometric affect structure predicted by the thesis actually appear? RSA between structural affect (Space A) and behavioral affect (Space C).
| Seed | range | Significant | Trend |
|---|---|---|---|
| 123 | -0.09 to 0.72 | 2/5 | Strong at low pop |
| 42 | -0.17 to 0.39 | 4/7 | Mixed |
| 7 | 0.01 to 0.38 | 5/7 | Increasing (0.01 to 0.24) |
Finding: Structure-behavior alignment in 8/19 snapshots. Seed 7 shows evolutionary trend. A-B alignment null (structure maps to behavior but not communication).
Source code
Study record — canonical metadata, result path, status, seeds, and key finding.
- — RSA computation
- — Runner
Experiment 8: Perceptual Mode and Computational Animism
Question: Do patterns develop modulable perceptual coupling? The earlier scalar “inhibition coefficient” is retired here in favor of the entity-indexed ascription field — how much agency a perceiver attributes to a target — with coupling and gain as the further, separately-measurable quantities. This experiment measures via the teleology bias in how patterns represent each target.
| Metric | Seed 123 | Seed 42 | Seed 7 |
|---|---|---|---|
| proxy (mean) | 0.27-0.44 | 0.27-0.41 | 0.31-0.35 |
| trajectory | 0.32 to 0.29 | 0.41 to 0.27 | 0.31 to 0.32 |
| Animism score | 1.28-2.10 | 1.60-2.16 | 1.10-2.02 |
Confirmed (in alone). High ascription is the default. Animism score > 1.0 in all 20 snapshots: patterns model resources using the same agent-template dynamics they use for other agents. Computational animism is the default because reusing the agent-template is the cheapest compression. Whether and covary with — the conjecture that replaced the old single-scalar assumption — is not settled by this measurement and remains open.
Source code
Study record — canonical metadata, result path, status, seeds, and key finding.
- — Ascription-field (alpha) measurement; legacy filename
- — Runner
Experiment 9: Proto-Normativity
Question: Does the viability gradient generate structural normativity?
Result: Null. No asymmetry between cooperative and competitive contexts. But (~4.9 vs ~3.1). Social context increases integration regardless of interaction type. Normativity requires agency — the capacity to act otherwise.
Source code
Study record — canonical metadata, result path, status, seeds, and key finding.
- — Normativity measurement
- — Runner
Experiment 10: Social-Scale Integration
Question: Does ?
Finding: No superorganism. Ratio 1-12% but increasing. Seed 7: 6.1% to 12.3% over evolution. Moving toward threshold but not reaching it.
Source code
- — Group integration measurement
- — Runner
Experiment 11: Entanglement Analysis
Question: Are world models, abstraction, communication, detachment, and self-modeling separable or entangled?
Finding: Four clusters — but not the ones predicted. Most measures cluster into one large group driven by population-mediated selection. Overall entanglement increases (mean |r| from 0.68 to 0.91). Everything becomes more correlated, just not in the clusters the theory expected.
Source code
Study record — canonical metadata, result path, status, seeds, and key finding.
- — Entanglement analysis
- — Runner
Experiment 12: Identity Thesis Capstone
Question: Does the full program hold in a system with zero human contamination?
| Criterion | Status | Strength |
|---|---|---|
| World models | Met | Weak (strong at bottleneck) |
| Self-models | Met | Weak (n=1 event) |
| Communication | Met | Moderate (15/21 sig) |
| Affect dimensions | Met | Strong (84/84) |
| Affect geometry | Met | Moderate (9/19 sig) |
| Tripartite alignment | Met | Partial (A-C pos, A-B null) |
| Perturbation response | Met | Moderate (rob 0.923) |
Verdict: All seven criteria met, most at moderate/weak strength. Geometry confirmed; dynamics undertested, blocked by the coupling wall.
Source code
Study record — canonical metadata, result path, status, seeds, and key finding.
- — Capstone integration
- — Runner